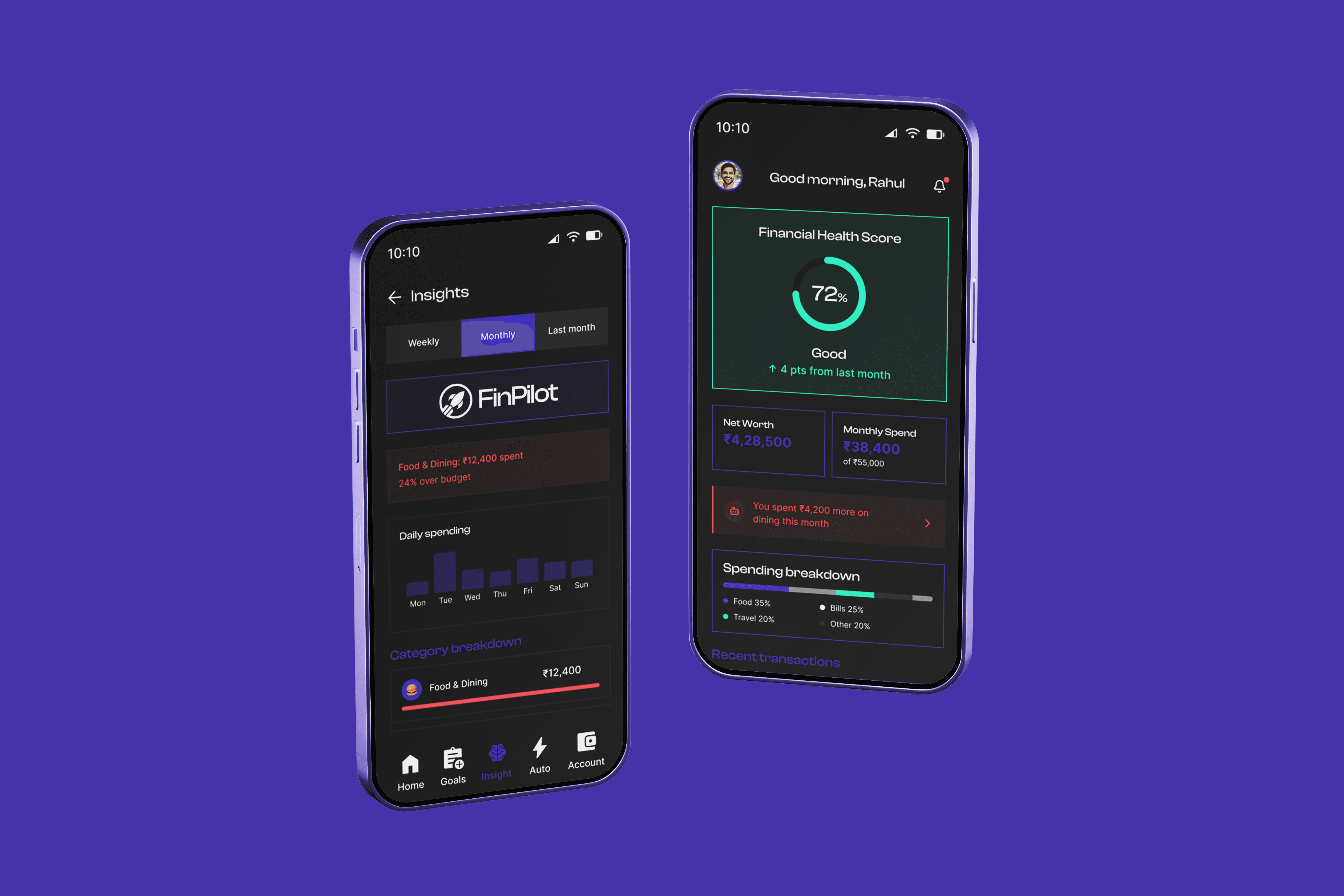
Project Atlas rebuilt a complex 6–8-hour production workflow into a scalable 90-minute AI-assisted pipeline without sacrificing human quality control.
Role
Senior Product Designer
Year
2024-25
Company
Amazon — Visual Innovation Team
Team
6 Designers · 2 Managers · QA Team · Senior AI Team (Seattle)
Tools Stack
Figma · AWS Bedrock · SageMaker · Adobe Firefly · Midjourney · Adobe Creative Suite
Atlas reduced AI-assisted product visualization time from 6–8 hours per ASIN to under 90 minutes, reduced rework cycles by nearly 50%, and increased weekly production throughput by 4–5× per designer.
Amazon Sellers with richer product visuals consistently saw stronger conversion and customer confidence, but producing those assets at catalogue scale was operationally unsustainable. Existing workflows relied on fragmented prompting methods, manual QA coordination, repeated correction cycles, and inconsistent quality standards across teams. Designers independently chose AI tools, prompt structures, and approval thresholds, making outputs difficult to audit, compare, or scale consistently.
01
High-quality visuals are directly tied to customer conversion, the business case for fixing this was unambiguous.
02
The operational review layer was where time went to die
03
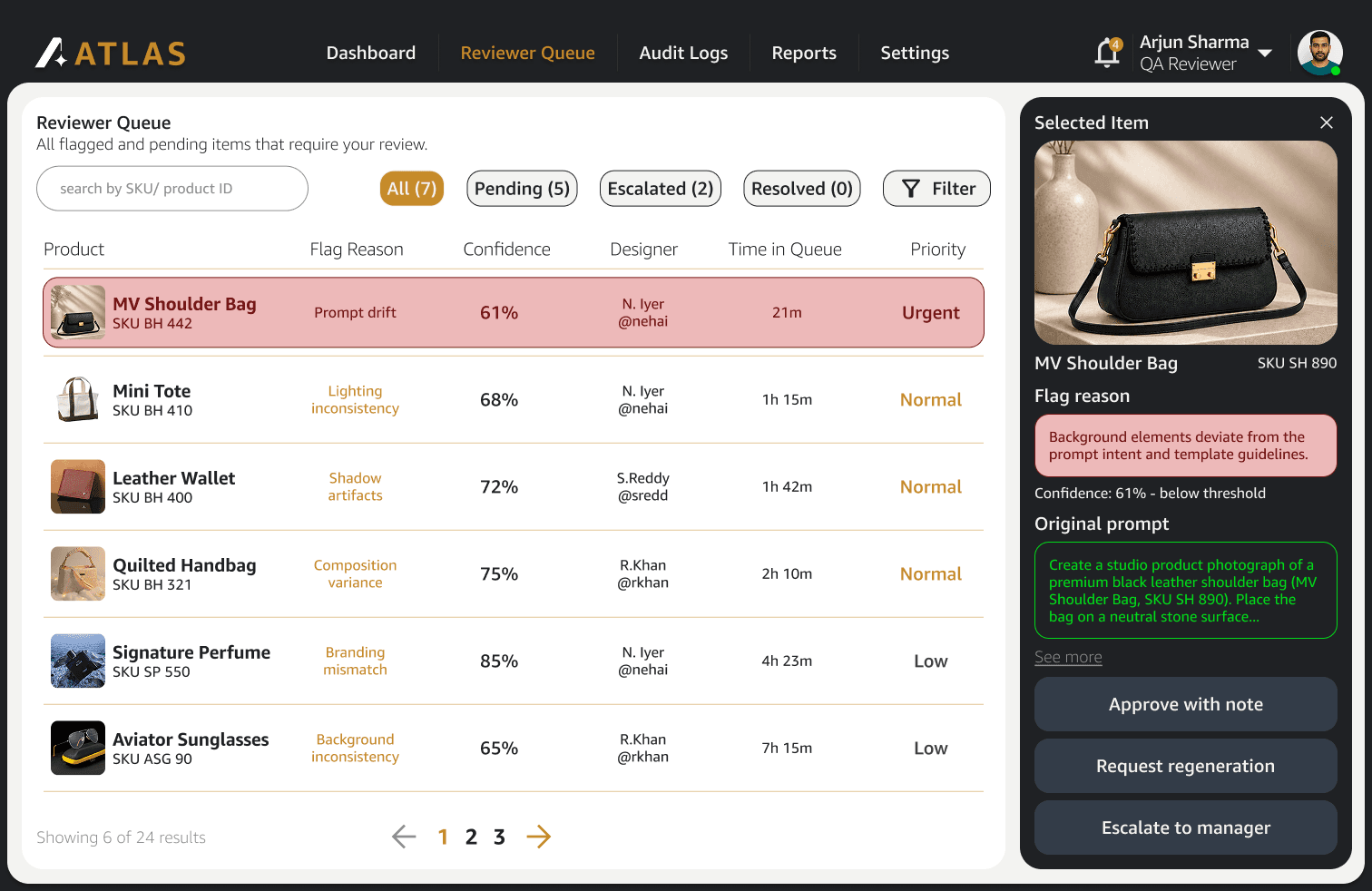
Reviewers lacked visibility into approval states, escalation paths, and queue priorities.

The defining decision was preserving human-in-the-loop review. Early testing showed that while automation improved throughput, it quietly reduced reviewer confidence and weakened quality governance during AI failure states such as prompt drift, inconsistent outputs, and hardware instability. Atlas also introduced standardized prompt structures and review systems that brought consistency across the team. Designers still retained creative flexibility, but generation inputs, approval logic, escalation paths, and QA visibility became structured, traceable, and less ambiguous.
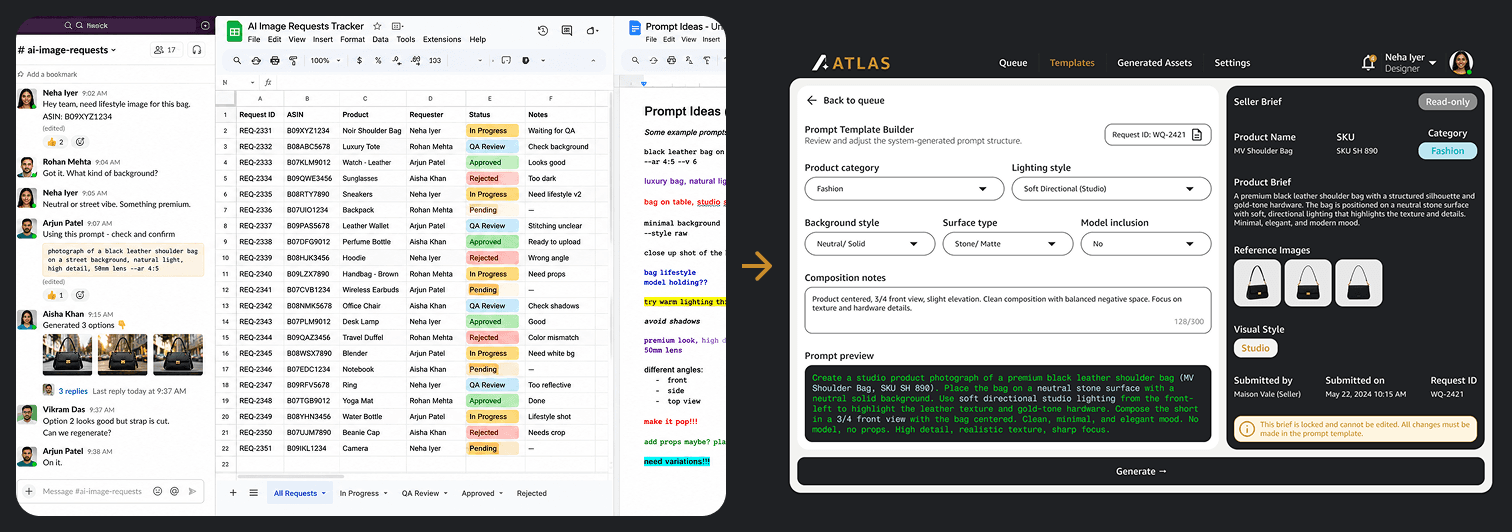
The Atlas system connected seller briefs, prompt frameworks, AI generation, QA validation, reviewer queues, and approval states into a single operational workflow. Structured rework logging categorized failures by prompt quality, model limitations, brief ambiguity, and QA inconsistencies, allowing recurring failure patterns to surface operationally instead of remaining anecdotal. One of the more important realizations during implementation was that the system needed to survive AI inconsistency rather than assume AI reliability. Model updates, distributed teams, hardware constraints, and prompt variability created operational instability that purely automated systems struggled to absorb. Atlas became significantly more resilient once escalation visibility and reviewer context were treated as first-class system components instead of secondary tooling.
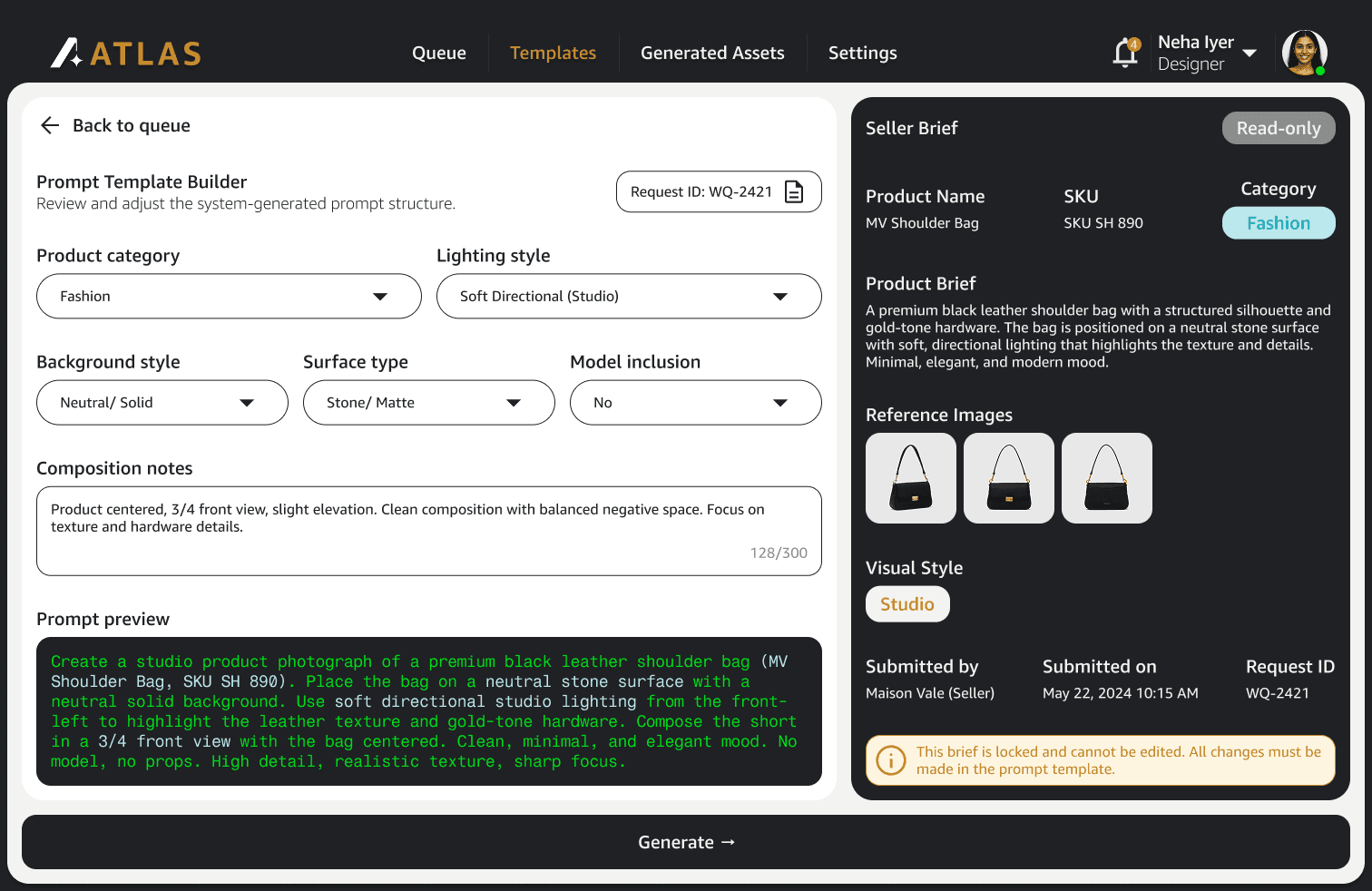
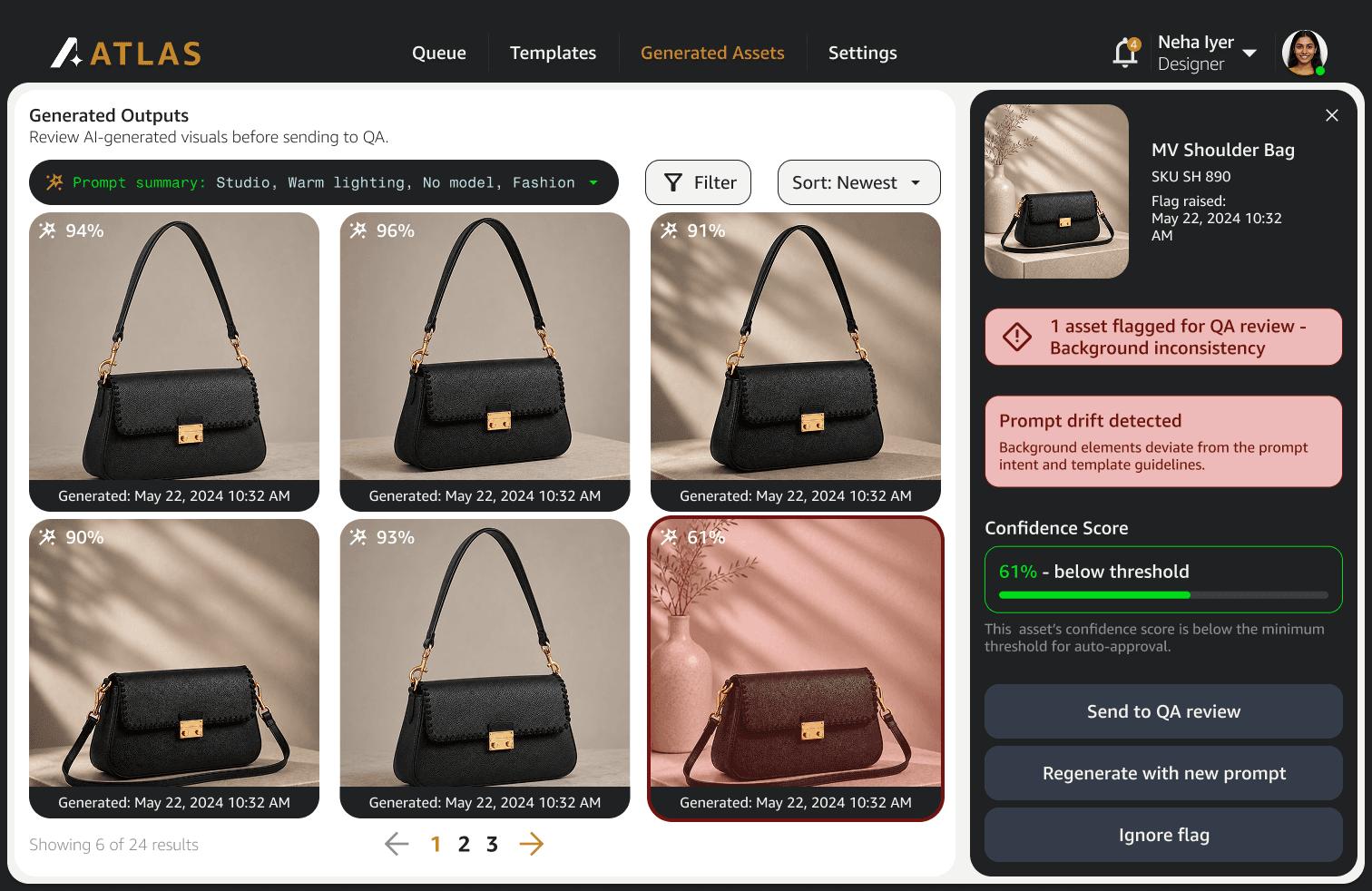
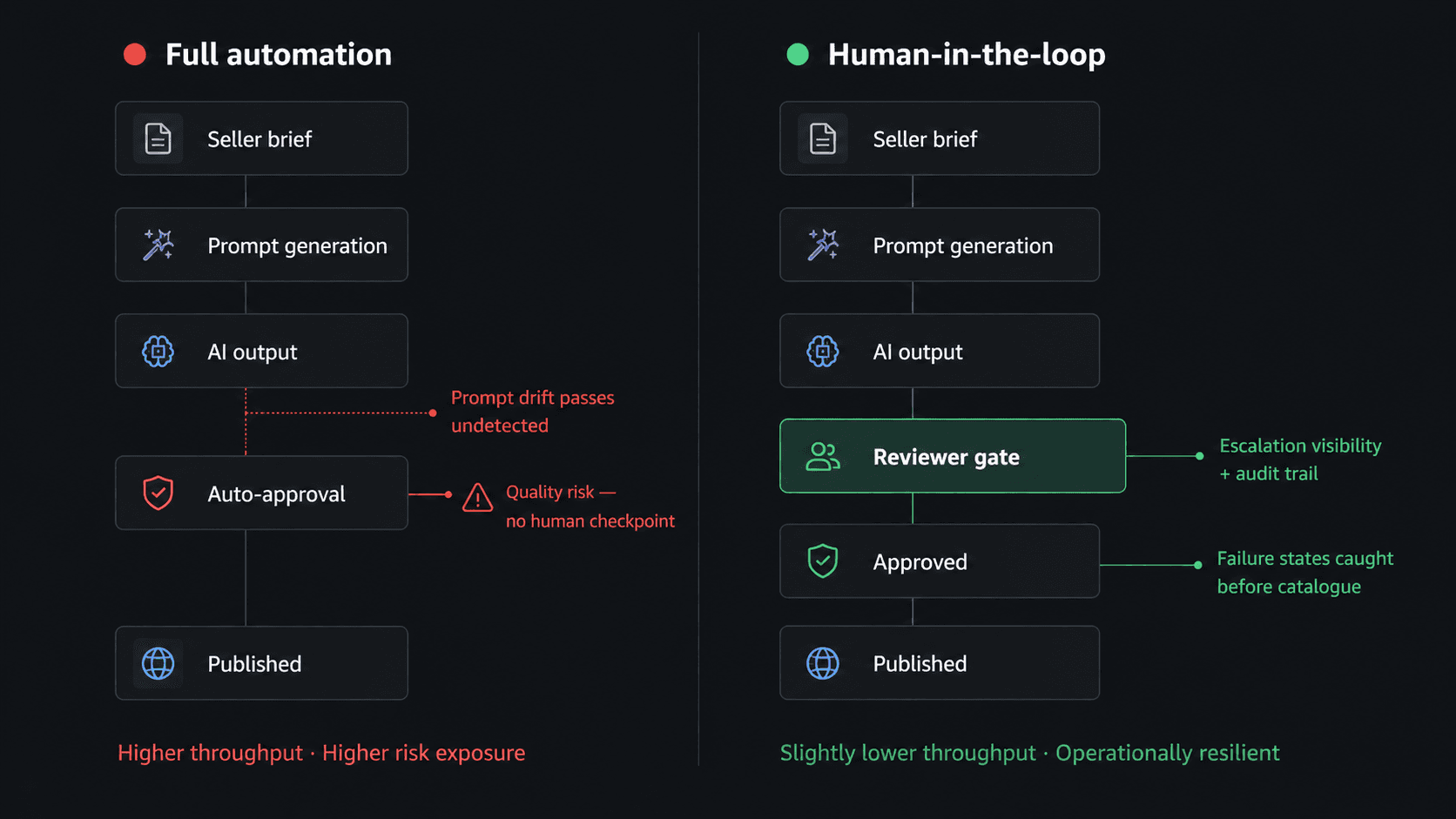
Fully automated approvals improved raw throughput metrics but increased quality-risk exposure at catalogue scale. We intentionally traded some efficiency for resilience. Prompt governance also created tension internally because standardization naturally constrains individual workflows. The solution was separating creative flexibility from operational consistency, allowing creativity to exist in interpretation and composition while standardizing review logic, escalation handling, and generation structure.
01
reduction in per-ASIN production time (6–8 hours → under 90 minutes)
02
fewer rework cycles after prompt standardization
03
more assets produced per designer per week
The most important UX work in Atlas never appeared on a polished hero screen. It lived inside reviewer confidence, escalation visibility, audit trails, and operational clarity during failure states. Designing AI systems at scale ultimately meant designing for the moments when AI performed unpredictably and making sure humans could recover quickly without losing trust in the system itself.
Check out the next project
A financial decision-support system designed around one idea: people don’t need more financial data — they need better financial orientation.